본 게시물은 '모두를 위한 딥러닝2' 강의를 듣고 정리한 글 입니다.
GitHub - shim-gaga/self-study
Contribute to shim-gaga/self-study development by creating an account on GitHub.
github.com
batch_size
컴퓨터가 한 번에 들고가서 처리할 양
Epoch
전체 훈련 데이터가 학습에 한 번 사용된 주기
Tensor Manipulation
1. Vector, Matrix and Tensor
딥러닝에서 다루는 기본적인 단위는 벡터, 행렬, 텐서이다.
차원이 없는 값을 스칼라(scalar)라고 하며, 1차원으로 구성된 값을 벡터라고 한다.
주로 3차원 이상을 텐서라고 하긴 하지만, 1차원 벡터나 2차원인 행렬도 텐서라고 표현하기도 한다.
ex. 벡터 = 1차원 텐서, 2차원 행렬 = 2차원 텐서
- 1차원: vector
- 2차원: matrix
- 3차원: tensor
2D Tensor (Typical Simple Setting)
행의 크기가 batch size, 열의 크기가 dim이다.

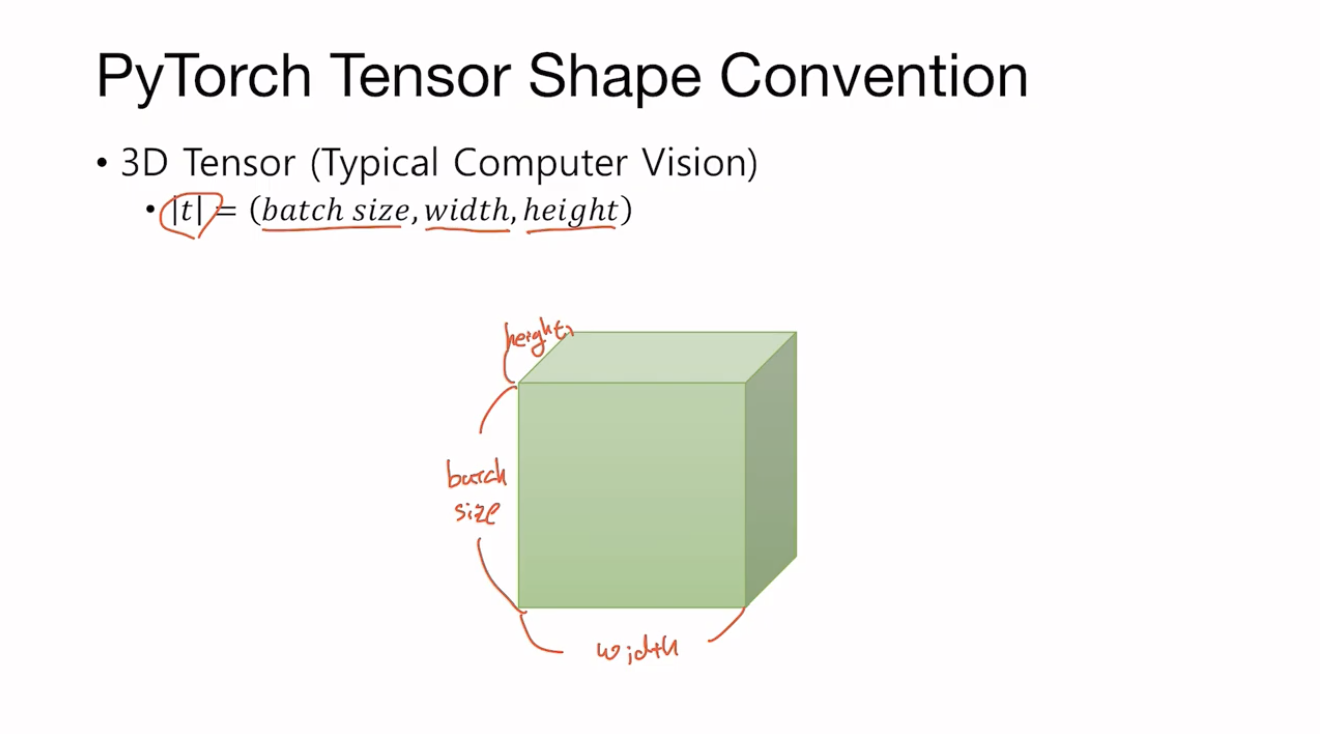
3D Tensor (Typical Computer Vision)
세로는 batch size, 가로는 width, 높이는 height이다.
3D Tensor (Typical Natural Language Processing)
NLP 분야에서의 3차원 텐서는 세로는 batch size, 가로는 length, 높이는 dim이다.
이러한 형태는 NLP과 시계열 데이터 등에서 주로 사용된다.
빗금으로 표시한 부분이 한 문장이며, 이 문장이 batch size만큼 쌓여있다고 볼 수 있다.

2. Broadcasting
Broadcasting은 다른 shape의 array operation에 numpy가 어떻게 대응하는지에 대해 묘사한 것이다.
특정한 조건 하에서 연산에 사용되는 array 중 더 작은 array가 larger array로 "broadcast"되어 계산가능한 shape을 갖게 된다.
아래의 조건이 맞으면 두 개의 tensor는 broadcastable 한다.
- 각 tensor는 최소 one dimension이상 가지고 있어야한다.
- dimension sizes를 iterate할 때에 dimension이 같거나 둘 중 하나가 1이거나 둘 중 하나가 없어야 한다.
만약 두 tensor 'x', 'y'가 broadcatable하다면 resulting tensor size는 아래와 같이 연산된다.
- x와 y의 차원이 같지 않을 때 같은 길이로 만들기 위해 차원이 작은 tensor의 차원을 한 차원 늘려준다.
- resulting dimension size는 차원에 따른 x와 y 사이즈의 최대값이 된다.
3. Operation
Matriix Multiplication vs. Multiplication
m1.matmul(m2)
행렬 곱셉
m1.mul(m2) or m1 * m2
원소 별 곱셉
Mean
t.mean() # 원소 전체의 평균
t.mean(dim=0) # 첫 번째 차원(column)에서의 평균
t.mean(dim=1) # 두 번째 차원(row)에서의 평균
t.mean(dim=-1) # 맨 마지막 차원에서의 평균
Sum
t.sum() # 원소 전체의 덧셈
t.sum(dim=0) # 첫 번째 차원(column)에서의 덧셈
t.sum(dim=1) # 두 번째 차원(row)에서의 덧셈
t.sum(dim=-1) # 맨 마지막 차원에서의 덧셈
Max
t.max() # 원소 전체의 최대값
t.max(dim=0) # 첫 번째 차원(column)에서의 최대값
t.max(dim=1) # 두 번째 차원(row)에서의 최대값
t.max(dim=-1) # 맨 마지막 차원에서의 최대값
.max()에서 dim 키워드를 사용하면 argmax도 함께 리턴하는 특징을 갖고 있다.
그래서 .max()의 0번째 인덱스는 max 값, 1번째 인덱스는 argmax 값이다.

* view(), squeeze(), unsqueeze()는 텐서의 원소 수를 그대로 유지하면서 모양과 차원을 조절한다.
View
PyTorch에서 텐서의 view는 NumPy에서의 reshape과 같은 역할을 한다.
즉, 원소의 수를 유지하면서 텐서의 크기를 변경한다.
조건은 다음과 같다.
- view는 기본적으로 변경 전과 변경 후의 텐서 안의 원소의 개수가 유지되어야 한다
- 파이토치의 view는 사이즈가 -1로 설정되면 다른 차원으로부터 해당 값을 유추한다.
ex. ft.view([-1, 3]) # (2, 2, 3) -> (4, 3)
Squeeze
1인 차원을 제거한다.
그러나 1이 아닌 차원을 제거하려고 하는 경우에는 제거되지 않는다.
ex. ft.squeeze() # (3, 1) -> (3,)
Unsqueeze
특정 위치에 1인 차원을 추가한다.
ex. ft.unsqueeze(1) # (3, ) -> (3, 1)
Type Casting
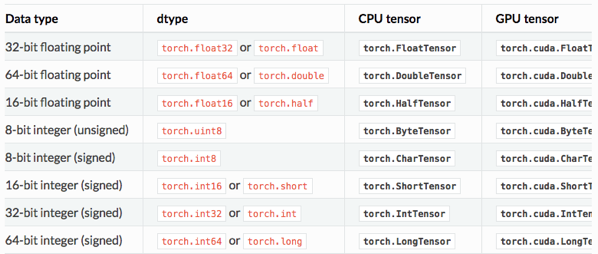
텐서에 .long(), .float(), .int() 등을 붙이면 해당 타입의 텐서로 변경된다.
텐서를 생성할 때는 .FloatTensor(), .IntTensor() 등을 사용하여 할당해주면 된다.
ex. lt = torch.LongTensor([1, 2, 3, 4])
lt.int()
Concatenate
두 텐서를 연결해주는데, 어느 차원을 늘릴지 지정할 수 있다.
지정하지 않으면 default로 dim=0의 차원을 늘린다.
ex. print(torch.cat([x, y], dim=0)) # (2, 2) -> (4, 2)
print(torch.cat([x, y], dim=1)) # (2, 2) -> (2, 4)
딥 러닝에서는 주로 모델의 입력 또는 중간 연산에서 두 개의 텐서를 연결하는 경우가 많다.
두 텐서를 연결해서 입력으로 사용하는 것은 두 가지의 정보를 모두 사용한다는 의미를 가지고 있다.
Stacking
concatenate를 하는 또 다른 방법으로는 stacking이 있다.
때로는 concatenate보다 stacking을 하는 것이 더 편리할 때가 있는데, 이는 stacking이 더 많은 연산을 포함하고 있기 때문이다.
# 두 연산은 동일
print(torch.stack([x, y, z]))
print(torch.cat([x.unsqueeze(0), y.unsqueeze(0), z.unsqueeze(0)], dim=0))
Ones_like, Zeros_like
0과 1로 채워진 텐서
ones_like를 하면 동일한 shape이지만 1으로만 값이 채워진 텐서를 생성한다.
zeros_like를 하면 동일한 shape이지만 0으로만 값이 채워진 텐서를 생성한다.
ex. print(torch.ones_like(x))
In-place Operation
연산 뒤에 _를 붙이면 기존의 값을 덮어쓰기 하는데, 메모리에 새로 할당하지 않고 원래의 tensor 값에 선언한다.
garbage collector가 pytorch에서 잘 구현되었기 때문에 속도 면에서 in-place operation을 사용하는 것이 그렇게 빠르지 않을 수도 있다.
ex. print(x.add_(2.))