모듈 import
import numpy as np
ndarray 변환
np.array()
array_1 = np.array([[1,2,3],
[2,3,4]])
ndarray.shape
차원과 크기를 튜플 형태로 반환
array_1.shape
ndarray.ndim
차원의 차수를 int 형태로 반환
array_1.ndim
ndarray의 데이터 타입
ndarray의 연산은 같은 데이터 타입만 가능
다른 데이터 유형이 섞여 있는 리스트를 ndarray로 변경하면 데이터 크기가 더 큰 데이터 타입으로 형 변환 일괄 적용
ndarray.dtype
ndarray의 데이터 타입을 <class 'numpy.dtype'> 형태로 반환
array1.dtype
ndarray.astype()
ndarray 내 데이터 타입 변경
메모리를 더 절약하기 위해 사용 ex) float -> int
array_float = array_int.astype('float64')
array_int1= array_float.astype('int32')
ndarray 편리하게 생성
ndarray.arange()
0부터 함수 인자 값 -1까지의 값을 순차적으로 ndarray의 데이터 값으로 변환
arange_array = np.arange(10)
# return: [0 1 2 3 4 5 6 7 8 9]
ndarray.zeros()
함수 인자로 튜플 형태의 shape 값을 입력하면 해당 shape를 가진 모든 값을 0으로 채운 ndarray 반환
함수 인자로 dtype을 정해주지 않으면 default로 float64 형의 데이터로 ndarray를 채움
zeros_array = np.zeros((3,2),dtype='int32')
# return: [[0 0]
# [0 0]
# [0 0]]
ndarray.ones()
함수 인자로 튜플 형태의 shape 값을 입력하면 해당 shape를 가진 모든 값을 1로 채운 ndarray 반환
함수 인자로 dtype을 정해주지 않으면 default로 float64 형의 데이터로 ndarray를 채움
ones_array = np.ones((3,2))
# return [[1. 1.]
# [1. 1.]
# [1. 1.]]
ndarray의 차원과 크기 변경
ndarray.reshape()
ndarray를 특정 차원 및 크기로 변환
-1을 인자로 사용하면 원래 ndarray와 호환되는 새로운 shape로 변환
-1 인자는 reshpape(-1, 1)과 같은 형태로 자주 사용
호환될 수 없는 형태는 변환할 수 없음 ex) (10,) -> (4, -1)
array1 = np.arange(10)
array2 = array1.reshape(2,5)
array3 = array1.reshape(5,-1)
ndarray 인덱싱
단일 값 추출
1개의 데이터 값을 선택하려면 ndarray 객체에 해당하는 위치의 인덱스 값을 [ ] 안에 입력
value = array1[2]
array2d[0, 0]
슬라이싱
':' 기호를 이용해 연속된 데이터를 슬라이싱해서 추출
':' 기호 앞에 시작 인덱스를 생략하면 자동으로 맨 처음 인덱스인 0으로 간주
':' 기호 뒤에 종료 인덱스를 생략하면 자동으로 맨 마지막 인덱스로 간주
# 1D
array1[3:]
array1[:]
# 2D
array2d[0:2, 0:2]
array2d[:, :]
팬시 인덱싱
팬시 인덱싱: 단일 값 추출 + 슬라이싱
리스트나 ndarray로 인덱스 집합을 지정하면 해당 위치의 인덱스에 해당하는 ndarray 반환
array2d[[0,1], 2]
array2d[[0,2], 0:2]
array2d[[0,1]]
불린 인덱싱
조건 필터링과 검색을 동시에 사용
[ ] 안에 조건을 적용
print(array1d > 5)
print(type(array1d > 5))
# return: [False False False False False True True True True]
<class 'numpy.ndarray'>array1d[array1d > 5]
행렬의 정렬
행렬 정렬
np.sort()
원 행렬은 그대로 유지한 채 원본 행렬의 정렬된 행렬 반환
기본적으로 오름차순으로 행렬 내 원소 정렬
내림차순으로 정렬하기 위해서는 np.sort()[::-1] 적용
# 1D
sort_array = np.sort(org_array)
sort_array = np.sort(org_array)[::-1]
# 2D
sort_array_axis0 = np.sort(array2d, axis=0) # row 방향으로 정렬
sort_array_axis1 = np.sort(array2d, axis=1) # column 방향으로 정렬
ndarray.sort()
원 행렬 자체를 정렬한 형태로 변환하며 반환 값은 None
내림차순으로 정렬하기 위해서는 array 자체에서 [::-1]
# 1D
org_array.sort()
org_array[::-1] # 내림차순 정렬
# 2D
array2d.sort(axis=0) # row 방향으로 정렬
array2d.sort(axis=1) # column 방향으로 정렬
array2d[:, ::-1] # 내림차순 정렬
정렬된 행렬의 인덱스 반환
np.argsort()
원본 행렬이 정렬되었을 때 기존 원본 행렬 원소에 대한 인덱스가 필요한 경우에 사용
정렬 행렬의 원본 행렬 인덱스를 ndarray 형으로 반환
내림차순으로 정렬 시 np.argsort()[::-1]
org_array = np.array([ 3, 1, 9, 5])
np.sort(org_array)
sort_index = np.argsort(org_array)
print(org_array)
print(sort_index)
# return: [1 3 5 9]
# [1 0 3 2]
예제
name_array=np.array(['John', 'Mike', 'Sarah', 'Kate', 'Samuel'])
score_array=np.array([78, 95, 84, 98, 88])
# score_array의 정렬된 값에 해당하는 원본 행렬 위치 인덱스 반환하고 이를 이용하여 name_array에서 name값 추출.
sort_indices = np.argsort(score_array)
print("sort indices:", sort_indices)
name_array_sort = name_array[sort_indices]
score_array_sort = score_array[sort_indices]
print(name_array_sort)
print(score_array_sort)
/*
return:
sort indices: [0 2 4 1 3]
['John' 'Sarah' 'Samuel' 'Mike' 'Kate']
[78 84 88 95 98]
*/
선형대수 연산
행렬 내적 (행렬 곱)
np.dot()
행렬 내적의 특성으로 왼쪽 행렬의 열 개수와 오른쪽 행렬의 행 개수가 동일해야 내적 연산 가능
A = np.array([[1, 2, 3],
[4, 5, 6]])
B = np.array([[7, 8],
[9, 10],
[11, 12]])
result = np.dot(A, B)

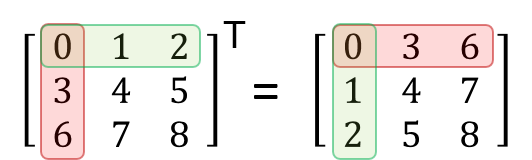
전치 행렬
np.transpose()
원 행렬의 전치 행렬 반환
A = np.array([[1, 2],
[3, 4]])
transpose_A = np.transpose(A)
'내가 보려고 만드는 > 파이썬' 카테고리의 다른 글
| [파이썬] 문자 아스키코드 변환 (0) | 2021.08.01 |
|---|---|
| [파이썬 - Pandas] 자주 쓰이는 함수 정리 (0) | 2021.07.31 |
| [파이썬] 리스트에서 최대 값과 최소 값의 index 찾기 (0) | 2021.07.24 |
| [파이썬] 문자열 리스트, 문자열 길이를 기준으로 정렬 (0) | 2021.07.24 |
| [파이썬] sort(), sorted() 함수 (0) | 2021.07.24 |